Buffer Overflow: Introduction
This week I decided to tackle a subject I’ve had difficulties with in the past. Reverse Engineering and binary exploitation have been a weak point of mine for a while now and I have been looking for an opportunity to get better at them.
In this article series we are going to study a simple buffer overflow attack and learn how it can lead to code execution via shellcode injection. Later on we will practice with CTF challenges in additional articles.
That being said, let’s go!
Buffer
Let’s start with the beginning: what is a buffer ?
A buffer is an area of computer memory used to store data, often while moving it from one section of a program to another, or between programs.
To illustrate we are going to take this very simple code example written in C:
1 |
|
Let’s break it down:
int main (int argc, char** argv): main function, taking command lines arguments as parameters.
char buffer [500];: create a 500 bytes buffer to hold data.
strcpy(buffer, argv[1]);: copy the first command line argument into our buffer variable.
return 0;: exit the program with status code 0.
We can now compile and test the program:
1 | [hg8@archbook ~]$ gcc vuln.c -o vuln |
Aand nothing happens.. but that’s expected. In order to have a simple as possible example, our program doesn’t have any print statement.
Now we have an easy and working example, before diving into the depth of buffer overflow let’s quickly review what an application memory looks like.
Memory Segmentation
Note: As of today the memory layout of a running application is more complex because of numerous security proactive measures. For learning purposes and this article’s examples, the security, such as Address Space Layout Randomization (ASLR) have been disabled to not interfere with the demonstration of the buffer overflow issue.
When you run a program, the processor is going to run several calculations depending on your program source code. To make the calculations as fast and efficient as possible it needs to store data in places that can be accessed very quickly. This will be either:
- Processor registry: On x86 (32 bits) we can note the common
EAX,EBX,EIP,ESP,EBP… Those are small memory spaces within the processor used for various purposes. - Random Access Memory (RAM): This is where the majority of information needed by your program is being stored: variables, pointers, stack, heap, etc.
Let’s take a look at a memory segmentation representation:

Explanations:
- The top area at the lowest address is called the
textsegment and contains the actual program code in machine instructions (asm). This area is read-only, which makes sense because you don’t want another process or a malicious person to change the program code on the run. - Below we have two
datasegments, one for the global initialized variables (ex:int global1 = 8;) and another one for global uninitialized variables (ex:int global2;). - Under the
datawe have theheapsegment. This area is used for large variable initialization (it can be images, files,malloc(), etc.) The growth ofheapmoves downward higher address depending on its need during program run. - The
stacksegment also has variable size and is used to temporarily store local function variables and context during function calls. The stack segment is an abstract data structure with LIFO ordering. The growth ofstackmoves upward lower address depending on its need during program run.
What is a buffer overflow?
We have now learned what a buffer is and understood the memory segmentation of a program. You may have started to guess what a buffer overflow is and how it can happen.
A buffer overflow occurs when data written to a buffer corrupts data values in memory addresses adjacent to the destination buffer. This can occur when copying data from one buffer to another without first checking that the data fits within the destination buffer.
Here is a visualization of a buffer overflow. Data is written into buffer A, but is too large to fit within A, so it overflows into buffer B.
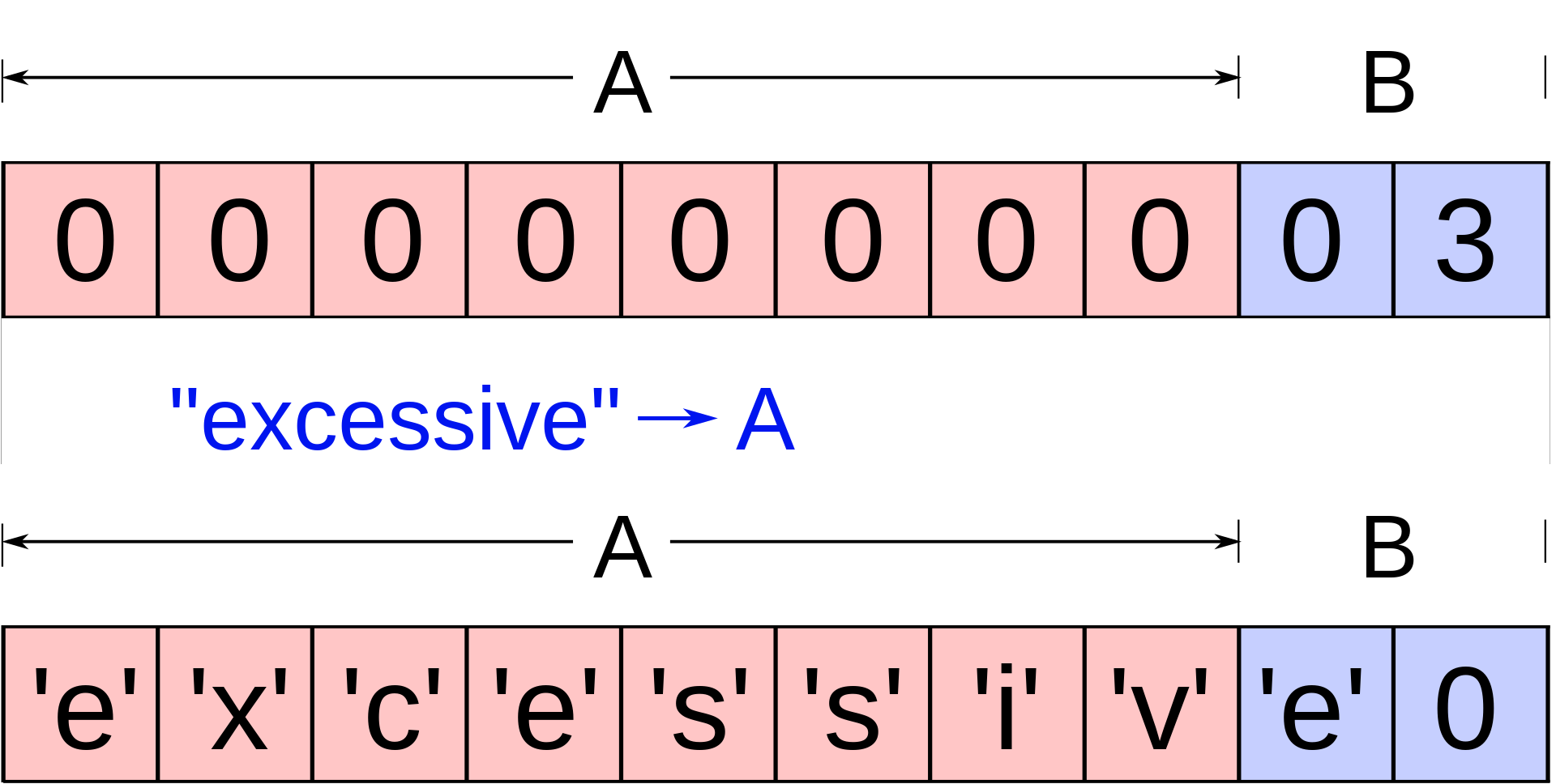
Identifying buffer overflow vulnerability
If you read our example code, you can notice where our buffer overflow will happen.
Indeed during the strcopy() of the command line argument into buffer[500], no length checks are being made. This means no matter the size of our argument, it will be copied into buffer variable.
So then, how would our program behave if we pass an argument longer than 500 bytes ? Let’s give it a try using python to generate a 501 bytes long string:
1 | [hg8@archbook ~]$ ./vuln AAA |
Interestingly we get no errors, but if we continue to add more data:
1 | [hg8@archbook ~]$ ./vuln $(python -c 'print("A"*508)') |
This time we get a segmentation fault at 508 bytes. Why 508 and not 501 ? Because of memory alignment. But we will talk about this later on.
A segmentation fault occurs when a program attempts to access a memory location that it is not allowed to access, or attempts to access a memory location in a way that is not allowed. This leads, in most cases, to a program crash.
Ok that’s great, it makes the program crash but how can we exploit this ?
The techniques to exploit a buffer overflow varies greatly depending on the architecture, OS and memory region. In this blog series, in order to keep it simple, we are going to focus on stack based buffer overflow on x86 architecture.
Our exploitation will consist in injecting malicious code (called shellcode) into our buffer and overwriting the return address of the stack segment to point to this injected shellcode.
References
- Buffer Overflow - Wikipedia
- Niagara Photo by Clay Banks